Die Aufgabe – Planungen und Berichte erstellen
Die meisten Finanzverantwortlichen und Controller schieben zu Beginn des Monats Überstunden, um alle zugesendeten Dateien zu konsolidieren, zu überprüfen und ggf. anzupassen. Die unterschiedlichen Dateien zu konsolidieren, Monat für Monat, ist ein mühsamer, ermüdender und vor allem fehleranfälliger Prozess.
Das Ziel – Viel Arbeit sparen durch automatisierten Import
Jeder hat schon davon geträumt, einen extra Mitarbeiter oder Praktikanten einzustellen, der ihm zuverlässig diese Arbeit abnimmt. Aber im Ernst, in Excel gibt es (ab Version 2016 bzw. v.16.0 standardmäßig) mit Power Query ein leistungsfähiges „Import-Tool“, das genau diese regelmäßigen Arbeiten schnell und verlässlich übernehmen kann.
Anm.: Anwender von Excel 2010 und 2013 können sich kostenlos ein Power Query Add-In auf der Seite von Microsoft herunterladen und installieren. Die Kompatibilität der in diesem Beitrag erläuterten Transformationen mit diesen veralteten Excel-Versionen wurde aber nicht geprüft und kann nicht garantiert werden.
Die Herausforderung – Unterschiedlich strukturierte Daten aus Vorsystemen
Im Idealfall sind die zu bearbeitenden Dateien (z.B. Excel-, csv- oder txt-Files) gleich aufgebaut bzw. strukturiert. D.h. jede Datei beinhaltet die gleichen Datenelemente und Spaltenüberschriften. In der Realität ist der Idealfall allerdings selten. Vielmehr sind die Ausgangsdaten häufig unterschiedlich strukturiert, da diese bspw. aus verschiedenen Vorsystemen stammen.
Im Folgenden wollen wir deshalb einen solchen realitätsnahen Fall am Beispiel der Konsolidierung von sog. offenen Posten (OPOS) aus verschiedenen Buchhaltungssystemen erläutern. Diese könnten dann bspw. in unserer „Liquiditätsplanung PREMIUM“ für eine umfassenden Forecast genutzt werden.
In dem hier gewählten Beispiel haben wir 3 verschiedene Gesellschaften, diese nutzen für ihre Finanzbuchhaltung Software von DATEV, Addison und Lexware Professional, so dass die jeweiligen Exportformate unterschiedliche Strukturen haben. Nicht nur stimmen die Spaltenbezeichnungen nicht überein, auch die Reihenfolge der Spalten ist unterschiedlich und auch die Spaltenanzahl divergiert. Darüber hinaus fehlen zum Teil Informationen (z.B. Angaben zur Währung).
Bevor man die Daten abrufen und transformieren kann ist es notwendig, ein „Zielformat“ bzw. eine Zielstruktur festzulegen. Hier sei eine konsolidierte Liquiditätsplanung mit dem Tool „Liquiditätsplanung PREMIUM“ beabsichtigt. Dabei wird die folgende Datenstruktur für die OPOS Debitoren verlangt (vgl. Abb. 1.1).

Abb. 1.1: Zielstruktur – Bezeichnungen und Reihenfolge der Spalten in finaler Tabelle
Damit sind nicht nur die exakten Spaltenüberschriften vorgegeben (wichtig für die automatische spätere Konsolidierung), sondern es wird (in diesem speziellen Beispiel) auch ein Währungskürzel verlangt (z.B. EUR, USD, CAD etc.) sowie ein Soll- bzw. Haben-Kennzeichen („S“ oder „H“) in Spalte H. Zu Weiterverarbeitung innerhalb des Tools „Liquiditätsplanung PREMIUM“ muss der Saldobetrag (Spalte F) immer positiv ausgewiesen werden. Dabei haben dann „normale“ Debitoren ein SOLL-Kennzeichen in Spalte H, kreditorische Debitoren (z.B. bei Verbuchung von Gutschriften) ein Haben-Kennzeichen.
Hört sich kompliziert an, ist aber genau die Logik des DATEV-Standardexportformates. Schließlich bekommen viele KMU ihre Daten von ihrem Steuerberater oder greifen von extern auf die Software „DATEV Kanzlei-Rechnungswesen“ zu.
Die Lösung – Eine Import-Prozedur die alle Ausgangsdaten in das Zielformat bringt
Schauen wir uns also die einzelnen Schritte an, um eine automatische Import-Prozedur zu erzeugen, die unabhängig von der Variabilität in den Datenstrukturen, den zuverlässigen Import und die Aufbereitung der Dateien gemäß der gewünschten Zielstruktur bewerkstelligt.
Am Ende dieses Beitrages finden Sie einen Link, der ihnen den kostenlosen Download der zugehörigen Excel-Dateien ermöglicht.
Wie das Anfügen von Daten in Power Query funktioniert
Das Anfügen von Tabellen unterschiedlicher Struktur kann mit Power Query zu unerwünschten Ergebnissen führen. Für das Verständnis ist es wichtig zu wissen, dass Power Query die Struktur der ersten Tabelle als eine Art Schablone bzw. Vorlage für den Aufbau der finalen Tabelle nutzt. Dabei werden diejenigen Spalten aneinander angefügt, welche dieselbe Spaltenbezeichnung haben. Da Power Query dabei auch „case sensitive“ ist, kommt es für ein korrektes Anfügen auch darauf an, dass die Groß- und Kleinschreibung bei den Spaltenbezeichnungen identisch ist (B ≠ b). Die Funktionsweise ist exemplarisch in Abb. 1.2 dargestellt.
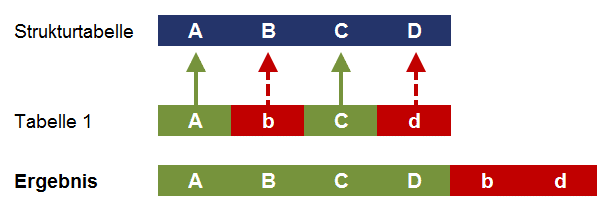
Abb. 1.2: Unterschiedliche Spaltenbezeichnung wird als „neue Spalte“ interpretiert
Sofern Spalten unterschiedliche Bezeichnungen haben (auch wenn dies nur die Groß- bzw. Kleinschreibung betrifft => Im Beispiel „b“ statt „B“ und „d“ statt „D“) werden diese als zwei unterschiedliche Spalten erkannt und nicht aneinander angefügt, sondern stattdessen wird für jede dieser (hier kleingeschriebenen) Spalten eine neue Spalte in der Ergebnistabelle angefügt.
Die exakt gleiche Spaltenbeschriftung der zu übernehmenden Spalten ist also für das Zusammenfügen unterschiedlicher Tabellen (hier DATEV-, Addison- und Lexware-Export) von zentraler Wichtigkeit.
Die Vorgehensweise im Überblick
Folgende 3 Schritte müssen der Reihe nach umgesetzt werden:
- Strukturtabelle als Vorlage definieren/importieren
- Exportdateien importieren und transformieren
- Abfragen hintereinander hängen und Daten zusammenfügen
Schritt 1
Strukturtabelle definieren bzw. importieren
Zunächst definieren wir für das anschließende Anfügeprozedere eine leere Strukturtabelle, deren einzige Aufgabe es ist, als Vorlage bzw. Schablone für die weiteren angefügten Tabellen zu dienen. In Excel kann diese Strukturtabelle einfach in einem Tabellenblatt manuell angelegt und in Power Query geladen werden. Alternativ kann man die Strukturtabelle auch direkt in M schreiben.
Der M-Code sehe in unserem Fall folgendermaßen aus:
= Table.FromRecords({[Debi Nr = null, Debi Name = null, Re Nr = null, Re Datum = null, Fälligkeit = null, Saldo = null, WKZ = null, SH Saldo = null]})
Die Tabelle enthält dann einen Datensatz mit NULL-Werten, der am Ende ggf. ausgefiltert werden muss. Wir nutzen im Weiteren die manuell erstellte Strukturtabelle, eine „intelligente“ Tabelle namens „Debi_Strukturtab“ die in der Datei „Strukturtabelle_Debi.xlsx“ abgespeichert ist.
Dazu klicken wir unter „Daten“ auf „Neue Abfrage“, „Aus Datei“, „Aus Arbeitsmappe“ (siehe Abb. 1.3) und wählen anschließend im Navigator die intelligente Tabelle namens „Debi_Strukturtab“ aus. Diese leere Tabelle haben wir vorher ganz normal in Excel gemäß unseren Wünschen bzw. Anforderungen erstellt (in diesem Beispiel ist eine spätere Verwendung der Daten in der Liquiditätsplanung PREMIUM das Ziel). Sie enthält auch die bei allen anderen Importdateien zu verwendenden Spaltennamen.

Abb. 1.3: Excel-Datei bzw. bestimmtes Arbeitsblatt in Power Query laden
Im Anschluss an die Selektion der gewünschten Daten besteht die Möglichkeit, die Daten über die Schaltfläche „Laden“ direkt in ein entsprechendes Ziel zu laden (ein Excel-Tabellenblatt, das Excel Datenmodell, oder beides parallel), oder vor dem Laden über die Schaltfläche „Bearbeiten“ noch Modifikationen an den Daten vorzunehmen. Da wir keine Veränderungen in der leeren Tabelle vornehmen wollen wählen wir „Laden in“, haken „Tabelle“ an und bestehendes Arbeitsblatt $A$1. Ein Klick auf „Laden“ fügt die Strukturtabelle in unsere Excel-Datei ein.
Schritt 2a
Exportdatei 1 (aus DATEV) importieren und transformieren
Schauen wir uns zunächst die zu importierende Rohdatei (OPOS_Debi_Unt_A_DATEV.xlsx) in Excel an, wird schnell klar, was bei den Daten transformiert werden muss.
Die Tatsache, dass viel mehr Spalten vorhanden sind als wir eigentlich benötigen, ist unproblematisch. Wichtig ist, dass alle erforderlichen Spalten, also auch Währungs- und Soll-/Haben-Kennzeichen bereits vorhanden sind. Nicht optimal ist das Format der beiden Spalten Rechnungsdatum und Fälligkeit (siehe markierte Zellen in Tabellenausschnitt => Abb. 1.4).
Zum Glück gibt es Power Query  und die Lösung (exemplarisch für die Spalte Rechnungsdatum) gestaltet sich wie folgt:
und die Lösung (exemplarisch für die Spalte Rechnungsdatum) gestaltet sich wie folgt:
- Zunächst öffnen Sie über „Daten“ => „Neue Abfrage“ => „Aus Datei“ => „Aus Arbeitsmappe“ unter Auswahl des gewünschten Inhaltes und Klick auf „Daten Transformieren“ die Rohdaten im Power Query-Editor.
- Dort markieren Sie die Spalte „Rechnungsdatum“.
- Klicken Sie im Menüband auf die Registerkarte „Start“ in der Gruppe „Transformieren“ auf den Pfeil neben Datentyp Ganze Zahl und wählen dann „Text“. Auf diese Weise werden die Zahlen ins Textformat konvertiert.
- Klicken Sie im Menüband auf die Registerkarte „Spalte hinzufügen“ in der Gruppe „Allgemein“ auf die Schaltfläche „Benutzerdefinierte Spalte“.
- Für die Umwandlung der Spalte „Rechnungsdatum“ geben Sie in dem Fenster im Textfeld „Neuer Spaltenname“ gleich die finale Bezeichnung „Re Datum“ ein. Im Textfeld „Benutzerdefinierte Spaltenformel“ geben Sie folgende Formel ein (vgl. auch Abb. 1.5):
=if Text.Length([Rechnungsdatum]) = 7 then Text.Start([Rechnungsdatum],1) & „.“ & Text.Range([Rechnungsdatum],1,2) & „.“ & Text.End([Rechnungsdatum],4)
else
Text.Start([Rechnungsdatum],2) & „.“ & Text.Range([Rechnungsdatum],2,2) & „.“ & Text.End([Rechnungsdatum],4)
Mit dieser Formel wird geprüft, ob die Einträge in der Spalte 7 Zeichen enthalten. Falls dies der Fall ist, wird in der neuen Spalte ein Datumswert aus der einstelligen Tages-, der zweistelligen Monats- und der vierstelligen Jahresangabe erzeugt. Falls die Einträge 8 Zeichen umfassen, wird der Datumswert aus der zweistelligen Tages-, der zweistelligen Monats- und der vierstelligen Jahresangabe abgeleitet.

Abb. 1.5: Transformation der Datumwerte mit benutzerdefinierter Formel
- Klicken Sie auf die Schaltfläche OK und die neue Spalte „Re Datum“ wird (ganz) rechts angefügt.
- Markieren Sie die Spalte durch Klick auf die Spaltenbeschriftung und stellen als Datentyp „Datum“ ein. Nun sollten die Datumswerte korrekt angezeigt werden.
Für die Spalte „Fälligkeit“ gehen Sie analog vor.
Das Aufräumen/Löschen nicht benötigter Spalten müssen wir nicht an dieser Stelle machen, sondern das erledigen wir später für alle importierten Dateien in einem Schritt.
Zwei Dinge müssen jetzt aber noch für diesen Import erledigt werden:
- Für alle später benötigten Spalten ist die finale Spaltenbezeichnung vorzugeben. Dazu kann entweder auf die bestehende Spaltenbezeichnung ein Doppelklick gemacht werden oder Sie wählen nach „Maus rechts“ auf die Spaltenbezeichnung den Eintrag „Umbenennen…“.
- Schließlich sollte jeweils der korrekte Datentyp eingestellt werden. Die beiden oben transformierten Datumsspalten sind ja bereits korrekt auf „Datum“ eingestellt. Für die Spalte „Saldo“ wählen wir „Dezimalzahl“, alle anderen Spalten, auch „Re Nr“ sollten den Datentyp „Text“ zugewiesen bekommen (Grund: Es gibt häufig alphanumerische Rechnungsnummern, die ansonsten Probleme bereiten würden, z.B. „Re34533A“ etc.).
Das war es mit den Transformationen zum Import der DATEV-Daten. Sofern noch nicht geschehen, sollten Sie der Abfrage einen selbsterklärenden Namen geben, hier z.B. „qry_Import_Debi_Unt_A_DATEV“. Klicken Sie abschließend im Menüband auf die Registerkarte „Start“ ganz links auf „Schließen&Laden“. Die Daten werden dann in ein neues Tabellenblatt geladen.
Schritt 2b
Exportdatei 2 (aus Addison) importieren und transformieren
Auch hier zunächst wieder ein Blick in die zu importierende Rohdatei (OPOS_Debi_Unt_B_Addison.xlsx). Es existiert zwar eine Spalte „Währung ISO-Code“ (Spalte T), dort sind aber keine Einträge bei den einzelnen Buchungen. Das kommt häufig in Fibu-Systemen vor, wenn ausschließlich in Euro gebucht wird. Die Datumswerte machen uns hier keine Schwierigkeiten, jedoch gibt es positive und negative Buchungsbeträge und ein Soll-/Haben-Kennzeichen fehlt deshalb.
Die erforderlichen Transformationen gilt es nun mit Hilfe von Power Query umzusetzen:
- Wie üblich öffnen Sie zunächst über „Daten“ => „Neue Abfrage“ => „Aus Datei“ => „Aus Arbeitsmappe“ unter Auswahl des gewünschten Inhaltes und Klick auf „Daten Transformieren“ die Rohdaten im Power Query-Editor.
- Als nächstes weisen wir PQ an, die erste Zeile der importierten Daten als Überschriften zu nutzen. Dazu klicken Sie im Menüband auf die Registerkarte „Transformieren“ in der Gruppe „Tabelle“ auf den Button „Erste Zeile als Überschriften verwenden“.
- Markieren Sie die Spalte „Buchungsbetrag“ und klicken Sie in der Registerkarte „Spalte hinzufügen“ in der Gruppe „Allgemein“ auf „Benutzerdefinierte Spalte“.
- Für den neuen Spaltennamen verwenden wir direkt die finale Bezeichnung „SH Saldo“, bei der benutzerdefinierten Spaltenformel tragen Sie ein (vgl. Abb. 1.6):
=if[#“Buchungsbetrag“]>=0 then „S“ else „H“

Abb. 1.6: Transformation aller Salden in positive Beträge
Dadurch wird für alle positiven Beträge ein Soll-Kennzeichen („S“), für alle negativen, also die kreditorischen Debitoren ein Haben-Kennzeichen („H“) in die neue Spalte eingefügt. Ein Klick auf „OK“ fügt die neue Spalte, wie üblich ganz rechts neben den bestehenden ein.
- Im nächsten Schritt müssen alle Buchungsbeträge zu positiven Werten transformiert werden. Wie im vorherigen Schritt wird dies über eine neue benutzerdefinierte Spalte gemacht. Der Spaltenname lautet hier „Saldo“, die Spaltenformel:
=Number.Abs([#“Buchungsbetrag“])
Dadurch werden alle Werte absolut, also positiv, ausgewiesen.
- Nun werden wir noch das Währungskürzel „EUR“ in die Zellen der Spalte „Währung ISO Code“ einfügen. Dazu markieren Sie die Spalte und klicken im Menüband auf die Registerkarte „Transformieren“ in der Gruppe „Beliebige Spalte“ auf „Werte ersetzen“. Im aufgehenden Fenster tragen Sie bei „Zu suchender Wert“ null ein, bei „“ EUR und bestätigen mit „OK“. Vergessen Sie nicht, diese Spalte später auch noch in „WKZ“ umzubenennen.
Das war es auch schon mit den „Spezialanpassungen“. Allerdings müssen auch hier, wie bereits beim Transformieren der DATEV-Daten abschließend wieder zwei Standardpunkte abgearbeitet werden (und zwar nur für die am Ende tatsächlich benötigten Spalten):
- Finale Spaltenbezeichnung => also Spaltenüberschriften umbenennen
- Korrekter Datentyp => Datum, Dezimalzahl und Text (je nach Spalte)
Schritt 2c
Exportdatei 3 (aus Lexware) importieren und transformieren
Auch hier zunächst wieder ein Blick in die zu importierende Rohdatei (OPOS_Debi_Unt_C_Lexware.xlsx). Das sieht insgesamt übersichtlich und aufgeräumt aus. In der ersten Zeile „stört“ eine Art Überschrift ein wenig, auch ist wieder eine Spalte mit Soll-/Haben-Kennzeichen zu ergänzen und anschließend müssen alle OP-Beträge positiv ausgewiesen werden. Das Währungskürzel ist hier bereits vorhanden.
Wir beschreiben hier deshalb lediglich den einzigen neuen Schritt, d.h. die Entfernung der ersten Zeile, die einzig den Hinweis „Lexware Professional – Offene-Posten-Debitoren 2020“ enthält. Für die restlichen Transformationen können analog zu den oben beschriebenen Erläuterungen und Hinweisen vorgehen. Das finale Ergebnis dieser Abfrage (natürlich inklusive aller Einzelschritte) können Sie sich auch in der Beispieldatei, die am Ende dieses Beitrages angefordert werden kann, ansehen.
Die einfachste Möglichkeit zum Entfernen der 1. Zeile ist ein Klick auf das Tabellensymbol oben links, direkt neben der ersten Spaltenbeschriftung (siehe roter Pfeil in Abb. 1.7).
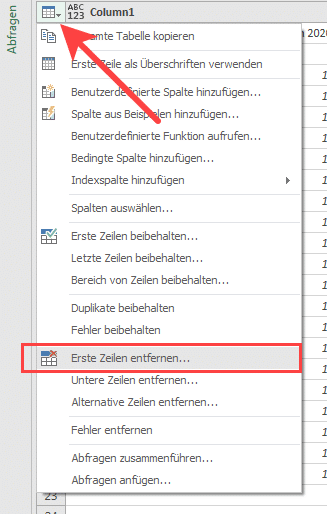
Abb. 1.7: Einfache Möglichkeit Überschrift bzw. erste Zeile zu entfernen
Anschließend wählen Sie den Menüpunkt „Erste Zeilen entfernen…“ und geben bei „Anzahl von Zeilen“ einfach den Wert 1 ein und schließen das Fenster mit OK. Als nächstes sollten Sie die (jetzt neue) erste Zeile als Überschriften verwenden (wie oben beschrieben) etc.
Zwischenstand
Wir haben nun 4 Blätter mit intelligenten Tabellen in unserer Datei, die Strukturtabelle sowie für die 3 Unternehmen die jeweiligen Importdaten. In den letzteren befinden sich jeweils noch zahlreiche Spalten, die wir nicht benötigen. Wir müssen diese aber nicht in jeder Abfrage löschen, sondern nutzen im Folgenden eine ganz bestimmte „intelligente“ und flexible Art der Zusammenführung.
Schritt 3
Abfragen hintereinander hängen und Daten zusammenfügen
Wie eingangs erläutert, sind durch das Prinzip des Anfügens von Daten in Power Query im Ergebnis häufig Spalten enthalten, die für die Weiterverarbeitung nicht interessant bzw. relevant sind. Eine Möglichkeit sich dieser überflüssigen Spalten zu entledigen besteht darin, diese in jeder Abfrage manuell zu entfernen. Diese tauchen dann im Ergebnis solange nicht wieder auf, bis irgendwann in den Quelldaten andere Spaltenüberschriften verwendet werden oder neue Spalten hinzukommen. Es erscheint sogar eine Fehlermeldung, wenn eine (oder mehrere) eigentlich nicht benötigte Spalte in den Quelldaten nicht mehr enthalten ist, weil dann die manuelle Löschaktion diese Spalte nicht mehr findet.
Im Gegensatz zur manuellen Löschmethode werden wir deshalb im Folgenden die Anfügetabellen mit Power Query automatisch an die Strukturtabelle anpassen. Damit ist sichergestellt, dass aus allen Anfügetabellen automatisch nur diejenigen Spalten akzeptiert bzw. übernommen werden, die in der Strukturtabelle vorhanden sind und das auch noch in der richtigen Reihenfolge.
Dazu ist folgendermaßen vorzugehen:
- Gehen Sie in den PQ-Editor ihrer Strukturtabelle und markieren die Spaltenüberschriften der gewünschten Spalten (hier also alle).
- Führen Sie mit der Maus einen Rechtsklick in einer der markierten Spalten aus und wählen den Menüpunkt „Andere Spalten entfernen“.
Nun müssen wir noch festlegen, dass in der finalen Tabelle auch nur diese Spalten erlaubt sind. Dies werden wir dynamisch machen, so dass im Fall einer späteren Erweiterung der Strukturtabelle um eine Spalte X, diese auch automatisch in der finalen Tabelle erlaubt bzw. wiederzufinden ist.
Dazu arbeiten wir mit der Funktion Table.SelectColumns in Kombination mit dynamischen Listen.
- Erstellen Sie mit einem Rechtsklick auf die Abfrage „qry_Strukturtabelle_Debi_laden“ zunächst einen Verweis auf die Strukturtabelle. Damit haben wir eine dynamische Liste von Spaltenüberschriften der Strukturtabelle.

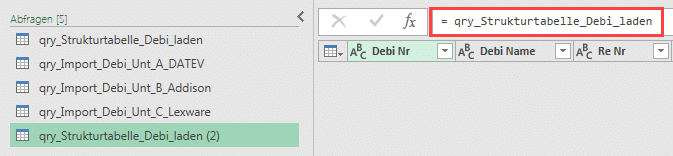
Abb. 1.8: Einen Verweis auf die Strukturtabelle setzen
Nachdem der Verweis erstellt wurde, lautet die Formel in der neuen Abfrage
= qry_Strukturtabelle_Debi_laden (rechts in Abb. 1.8).
Dies hat zur Folge, dass jede Änderung, die in der Strukturtabelle vorgenommen wird, automatisch die Struktur der neu erstellten Tabelle beeinflusst. Ziel ist eine Liste mit den Spaltenbeschriftungen, dazu nutzen wir die Funktion Table.ColumnNames(). Das Resultat sieht wie folgt aus:

Abb. 1.9: Spaltenbezeichnungen in eine Liste einlesen: Table.ColumnNames()
In Schritt 2 (siehe Abb. 1.9) wird die Abfrage direkt „Liste_Sollbezeichnung_Spalten“ benannt. Dies führt automatisch zur Umbenennung in Schritt 3. Damit haben wir eine Liste mit Spaltenbezeichnungen der Strukturtabelle, die sich automatisch an Veränderungen in der Strukturtabelle anpasst.
Diese dynamische Liste kann nun zur Erstellung der finalen Tabelle wie folgt genutzt werden.
- Zunächst öffnen Sie über „Daten“ => „Neue Abfrage“ => „Abfragen kombinieren“ => „Anfügen“ und klicken dann den Button „Drei oder mehr Tabellen“ an. Wählen Sie dann aus den verfügbaren Tabellen die 3 Abfragen der Unternehmen A bis C, klicken auf „Hinzufügen“ (vgl. Abb. 1.10) und schließen das Fenster durch Klick auf OK.

Abb. 1.10: Mehrere Abfragen kombinieren bzw. anfügen
- Zunächst öffnen Sie über „Daten“ => „Neue Abfrage“ => „Abfragen kombinieren“ => „Anfügen“ und klicken dann den Button „Drei oder mehr Tabellen“ an. Wählen Sie dann aus den verfügbaren Tabellen die 3 Abfragen der Unternehmen A bis C, klicken auf „Hinzufügen“ (vgl. Abb. 1.10) und schließen das Fenster durch Klick auf OK.
- Wir haben nun die 3 Abfragen kombiniert (vgl. Abb. 1.11), müssen aber noch im nächsten Schritt die Table.SelectColumns()-Funktion einfügen.

Abb. 1.11: Ergebnis nach Anfügen aller 3 Abfragen für die Rohdaten
- Die Table.SelectColumns()-Funktion lässt sich direkt manuell einfügen und hat grundsätzlich die folgenden Parameter:
Table.SelectColumns(table as table, columns as any, optinal missingFiled as nullable number) - „missingField“ ist ein optionaler Parameter den wir nicht benötigen, für „columns as any“ fügen wir den Namen unserer dynamischen Liste ein (vgl. Abb. 1.12). Außerdem können wir bei dieser Gelegenheit noch die Abfrage auf der rechten Seite in z.B. „Finale_Daten“ umbenennen.

Abb. 1.12: Die Liste erlaubter Spalten dynamisieren: Table.SelectColumns()
Ein Klick auf „Schließen&Laden“ sollte dann zum gewünschten Ergebnis in einem Excel-Tabellenblatt führen. In unserer Beispiel-Datei heißt dieses Blatt „Ergebnis“.
Abschließende Bemerkungen
In unserer kostenlos herunterladbaren Beispiel-Datei haben wir aus didaktischen Gründen die Abfragen für die einzelnen Unternehmen immer auch in ein separates Tabellenblatt geladen. Da wir nur am Endergebnis interessiert sind, ist dies eigentlich nicht erforderlich. Somit können die Tabellenblätter „Strukturtabelle“, „A DATEV“, „B Addison“ sowie „C Lexware“ (nicht die Abfragen!) auch aus der Datei gelöscht werden. Lediglich das Blatt „Ergebnis“ sowie alle in der Excel-Datei enthaltenen Abfragen werden für die Weiterverarbeitung benötigt. Wir haben die oben genannten Tabellenblätter dennoch in der Demo-Datei gelassen, damit Sie sich die Zwischenergebnisse einfacher ansehen können.
Für das in diesem Beitrag erläuterte Beispiel lagen die Rohdaten als Excel-Dateien vor (*.xlsx). Das hier gesagte gilt aber analog bei Ausgangsdaten im csv- oder txt-Format. Es ist sogar möglich bspw. von Unternehmen A eine csv-Datei, von Unternehmen B eine txt-Datei und von Unternehmen C eine xlsx-Datei zu verarbeiten. Selbstverständlich könnten noch beliebig viele weitere Unternehmen ergänzt werden, wobei die Anzahl der enthaltenen Datensätze pro Datei durchaus Tausend und mehr betragen kann. Am Ende lässt sich alles mit einem Klick (Alle Aktualisieren) auf den neuesten Stand bringen.
Noch Hinweis für die Verwendung der Download-Datei. Je nachdem wo Sie diese auf ihrem Rechner speichern, finden die Abfragen natürlich die Rohdaten nicht (da anderer Pfad). Dies lässt sich aber relativ einfach in den „Datenquelleneinstellungen“ ändern.
Gehen Sie dazu über „Daten“ => „Neue Abfrage“ => „Datenquelleneinstellungen…“. In dem sich dann öffnenden Fenster können Sie die Pfade zu den Rohdaten-Dateien schnell anpassen (siehe rote Markierung in Abb. 1.13).

Abb. 1.13: Datenquellen / Pfad für Rohdaten einstellen / ändern
Gehen Sie dazu über „Daten“ => „Neue Abfrage“ => „Datenquelleneinstellungen…“. In dem sich dann öffnenden Fenster können Sie die Pfade zu den Rohdaten-Dateien durch einen Klick auf „Quelle ändern…“ schnell anpassen.
Holen Sie sich zum Ausprobieren am besten gleich die von uns bereitgestellte Exceldatei.
